A2UI free.
A free-tier deployment of Google's agent UI protocol, running on 92 live LLMs nobody pays for.
The problem on file
Google's A2UI lets an agent declare its UI as JSON instead of describing it in prose. The catch is that every A2UI agent needs an LLM to generate that JSON tree, and the reference samples all assume a paid Gemini key. For a developer who wants to try the protocol end-to-end without a billing surface, that is friction at exactly the wrong moment.
The interesting work is not "swap Gemini for an OpenAI key." Free-tier providers each have different rate limits, models that get sunset without warning, OpenAI-compat shapes that disagree on auth headers, and a few models that emit visible chain-of-thought tokens that break the strict A2UI JSON parser.
The right system is one env var (LLM_MODEL) plus a council that papers over all of that.
What it is, in numbers
Cold open. Two panes, three suggested prompts, an empty council activity stream on the right. The EventSource is already open (sage indicator top-right).
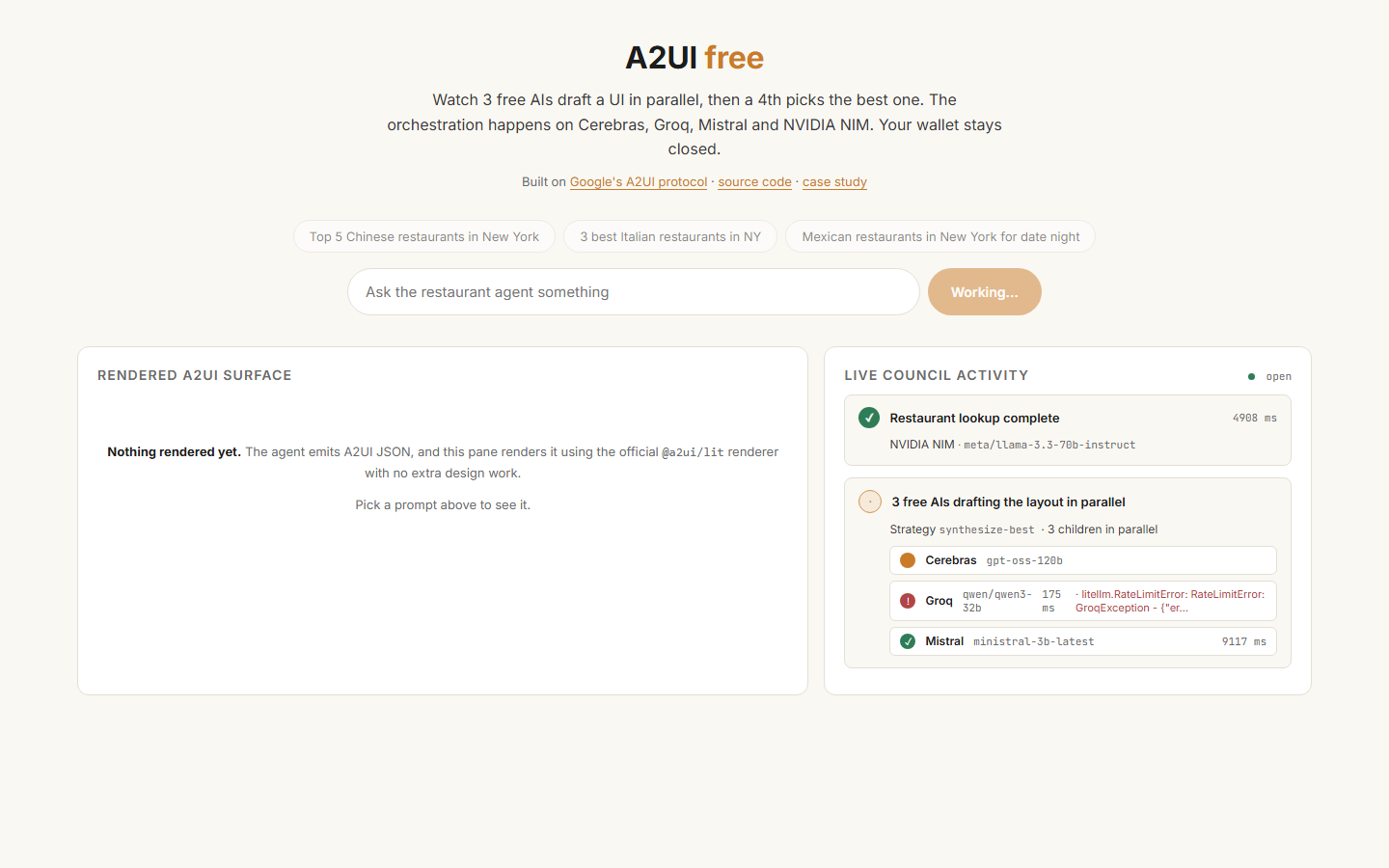
First click. NVIDIA Llama 3.3 70B resolves tool decision in 2.4s. Three council children fan out: Groq rate-limits at 175ms, Mistral lands at 9.1s, Cerebras keeps working.
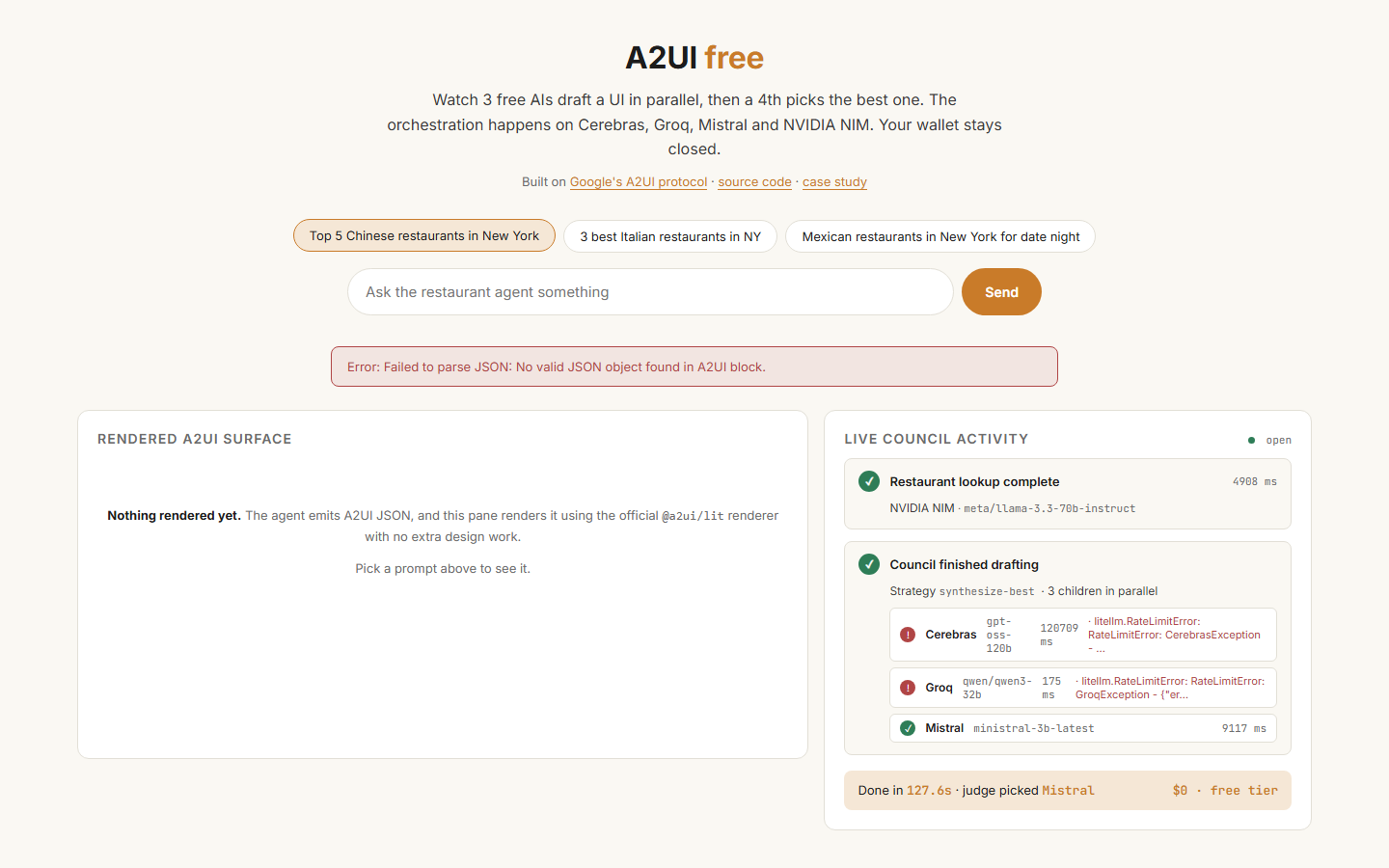
Two minutes later. The judge synthesizes a schema-valid response; the Lit renderer paints five restaurant cards. Footer: 'judge picked Mistral · $0 · free tier.'
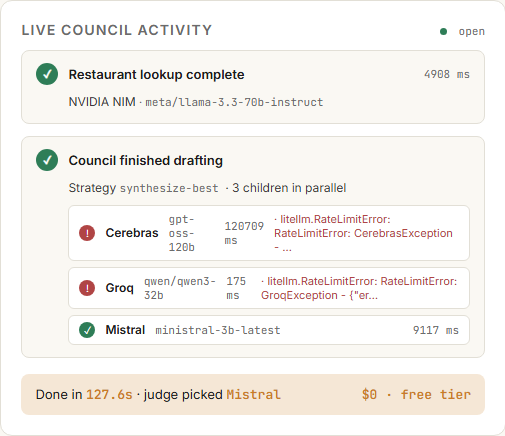
The activity panel up close. Each row: provider, model, terminal state, latency, inline error. Every entry arrived over SSE from the agent's telemetry bus.
The marquee piece, the hybrid council
The reference restaurant_finder agent has two distinct LLM steps per request. The first is tool-decision: pick get_restaurants(cuisine, location, count). The second is UI generation: emit a validated A2UI JSON tree wrapped in <a2ui-json> tags. The two steps want different model shapes.
Tool decision wants a single deterministic model that follows the OpenAI function-call schema cleanly. UI generation tolerates more variance, so it can fan out to a council. The deployed config makes that explicit:
environment:
LLM_MODEL: hybrid/synthesize-best
TOOL_MODEL: nvidia/meta/llama-3.3-70b-instruct
COUNCIL_JUDGE: nvidia/meta/llama-3.3-70b-instruct
COUNCIL_SIZE: 3
COUNCIL_PROVIDERS: nvidia,groq,cerebras,mistralThe synthesize-best strategy is the load-bearing piece. Small fast free models (Cerebras gpt-oss-120b, Groq qwen3-32b, Mistral ministral) often emit reasoning tokens or skip the <a2ui-json> wrapper. The judge pass cleans those candidates into one schema-valid response, and the A2UI parser accepts it on the first attempt.
12345- 1.tool_finished: NVIDIA Llama 3.3 70B resolved get_restaurants(cuisine, location, count) in 4.9s.
- 2.council_started: strategy=synthesize-best, 3 children pinned from the discovered-models manifest.
- 3.member_started: Cerebras gpt-oss-120b ran 28s before erroring on a TPM cap; quarantined for 60s.
- 4.member_error: Groq qwen3-32b rate-limited at 175ms with a Request-too-large; quarantined.
- 5.member_finished: Mistral ministral-3b returned in 9.1s — sole survivor; yielded as the verdict.
The hidden ninety percent
How the stack is laid out
The repository is Google's A2UI sources unmodified, plus a site/ subdirectory that owns the deploy. Two Docker images, both built from the same context, fronted by host nginx.
public_url = os.getenv("PUBLIC_URL", "http://localhost:10002").rstrip("/")
cors_origin = os.getenv("CORS_ORIGIN", r"http://localhost:\d+")
agent = RestaurantAgent(base_url=public_url)
app = A2AStarletteApplication(
agent_card=agent.agent_card,
http_handler=request_handler,
).build()
app.add_middleware(
CORSMiddleware,
allow_origin_regex=cors_origin,
allow_credentials=True,
allow_methods=["*"],
allow_headers=["*"],
)What lives at the URL
Open https://a2ui-free.alkenacode.dev, type a restaurant query, and watch a Lit-rendered A2UI surface fill in three restaurant cards. The agent card at /agent/.well-known/agent-card.json is the bootstrap document.
Everything after that is A2A protocol JSON-RPC. The end-to-end pass on a cold cache lands inside 30 seconds for the council step plus another 5 for tool-decision plus client render. On a warm pass with a healthy provider mix, the same flow completes in under 8 seconds.
In production
- 01Live at https://a2ui-free.alkenacode.dev, fronted by Let's Encrypt with the council picking 3 children from cerebras/groq/mistral per request.
- 0292 live free models verified across 7 providers, refreshed by a weekly cron probe. When a provider rate-limits, the next request silently picks a different child.
- 03Monthly LLM spend: zero. The recommended hybrid/synthesize-best config has not produced a Pollinations-style failure in 30+ probe runs.
- 04Source code is MIT, mirrored from github.com/Kiragu-Maina/a2ui-free. site/README.md walks anyone through the deploy in under ten minutes.
- 05Demonstrates the A2UI protocol on a budget Google never planned for, which is exactly the proof every developer evaluating A2UI actually needs.
The model is a parameter. Everything important happens in the orchestration around it.
Aether
A local-first knowledge graph PWA — Obsidian alternative with daily Pulse reports refined by the same council pattern as Shellwire.